Lösung · Dokumenten-Pipeline
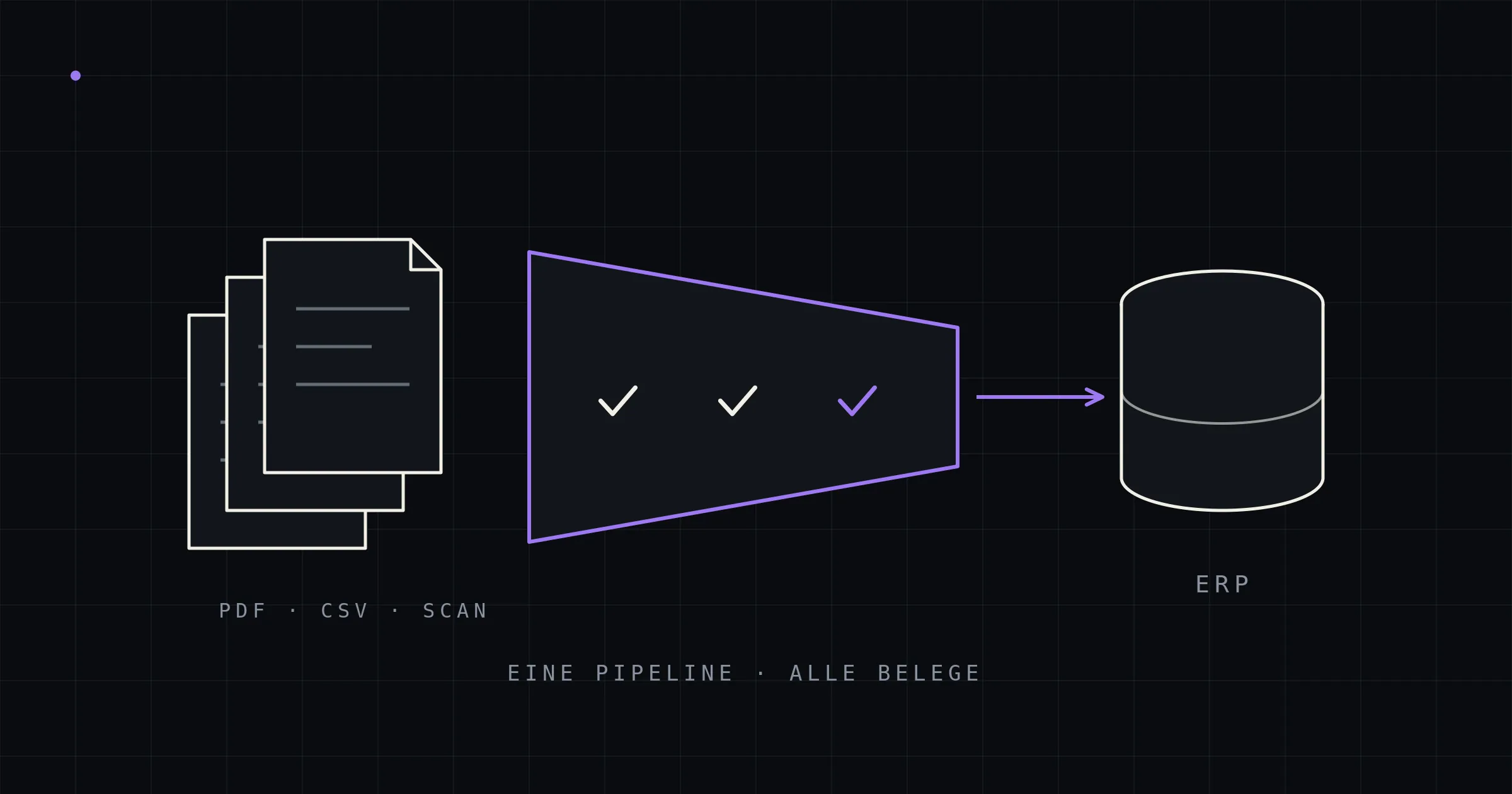
PDF-Belege rein. Geprüfte ERP-Buchungen raus.
Bestellungen, Rechnungen und Lieferscheine kommen als PDF — und werden im Innendienst abgetippt. Die kitun Dokumenten-Pipeline liest sie template-frei mit lokaler KI, prüft jede Position deterministisch und legt sie direkt in eurem ERP an: kein Dokument verlässt euer Netzwerk, keine Gebühr pro Beleg.
- Template-frei
- Neue Absender ohne Einrichtung
- On-premise
- Open-Weights-Modelle auf eurer Hardware
- 0 % unentdeckte Fehler
- Als Betriebsziel, nicht als Werbeversprechen
- Keine Stückpreise
- Fixe Kosten statt Volumenstaffeln
- Direkt im ERP
- Anlage über offizielle Schnittstellen
Der teuerste Prozess, der in keiner Auswertung steht
In einem typischen Industrieunternehmen mit 40 Belegen pro Tag bindet manuelle Erfassung rund 4 Arbeitsstunden täglich — knapp 40.000 Euro pro Jahr, bevor der erste Erfassungsfehler zur Falschlieferung wird. Dazu kommen Fehlerfolgekosten, verfallene Skonti und ein Innendienst, der tippt statt verkauft. Die vollständige, nachrechenbare Rechnung: Was kostet manuelle Belegerfassung wirklich?
Und das Problem löst sich nicht von selbst: Die E-Rechnungspflicht strukturiert nur Rechnungen, nur in Deutschland, mit Übergangsfristen — Bestellungen, Lieferscheine und der gesamte Schweizer Belegverkehr bleiben PDF. Hintergrund →
So funktioniert die Pipeline
Eingang & Weiche
Belege kommen per Postfach, Ordner oder Scan. Dubletten werden per Datei-Hash aussortiert, bevor Rechenzeit anfällt. Bereits strukturierte Eingänge (E-Rechnungen, CSV) laufen deterministisch — KI nur dort, wo sie gebraucht wird.
Extraktion, lokal
Layout-Parsing und template-freie Extraktion mit Open-Weights-Modellen auf eurer Hardware. Das Modell schreibt ab, was im Beleg steht — es rechnet und rät nicht.
Deterministische Validierung
Jede Position wird nachgerechnet (Menge × Preis = Summe), jeder Wert gegen den Originaltext belegt, Artikel- und Partnernummern gegen eure Stammdaten aufgelöst. Mathematik findet Zahlendreher zuverlässiger als jedes Review.
Anlage im ERP
Geprüfte Belege entstehen über die offiziellen Schnittstellen eures Systems — als Verkaufsauftrag, Eingangsrechnung oder Wareneingang, mit Quellbeleg verknüpft. Unsichere Belege landen vorausgefüllt in einer Review-Maske: prüfen in Sekunden statt abtippen in Minuten.
Vertiefung: Der komplette Leitfaden · Die technische Anatomie
Das Qualitätsversprechen — und warum es anders klingt als üblich
Anbieter werben mit „99 % Genauigkeit“. Wir nicht — denn die Zahl beantwortet die falsche Frage. Unser Betriebsziel: null unentdeckte Fehler unter den automatisch übernommenen Belegen. Fehler dürfen passieren; sie dürfen nur nicht unbemerkt passieren. Dafür sorgt die Validierungsschicht — nicht das Modell. Typischer Verlauf: 70–90 % der Belege laufen ab Start vollautomatisch durch, die Quote steigt mit jeder Korrektur. Warum „99 %“ die falsche Frage ist →
Souverän by design
Belege sind konzentrierte Geschäftsgeheimnisse — Konditionen, Preise, Kundenbeziehungen. Deshalb läuft die Pipeline vollständig on-premise: Open-Weights-Modelle auf einer GPU-Workstation oder kompakten KI-Appliance (Größenordnung wenige tausend Euro), kein Cloud-Dienst, kein AV-Vertrags-Geflecht, DSGVO- bzw. revDSG-konform by design. Das Modell bleibt austauschbar — nicht an einen Modell-Anbieter gebunden. On-Premise im Detail →
Eine Pipeline, alle Belegarten
- Kundenbestellungen → Verkaufsaufträge. Der größte Hebel: positionsgenau, mit Auflösung fremder Artikelnummern — ohne dass Kunden ihr Verhalten ändern. Mehr →
- Eingangsrechnungen — hybrid. Echte E-Rechnungen deterministisch, freie PDFs (Ausland, Schweiz, Übergangsfälle) per Extraktion; dieselben Prüfungen für alles. Mehr →
- Auftragsbestätigungen & Lieferscheine. Positionsweiser Abgleich gegen die Bestellung — Abweichungen bei Preis, Menge, Termin werden gemeldet, solange Reaktion möglich ist. Mehr →
- Der EDI-Long-Tail. EDI für die Großen, Pipeline für alle anderen — Geschäftspartner bestellen weiter wie immer. Mehr →
Die Pipeline ist der spezialisierte Belegerfassungs-Fall — für Agenten jenseits der Belege (Vertrieb, Recherche, Kundenservice): KI-Agenten-Entwicklung →
Direkt in euer ERP — über offizielle Schnittstellen
Keine Portale, keine CSV-Umwege: Die Pipeline schreibt über die dokumentierten Integrationswege eures Systems, damit jede Geschäftsregel greift wie bei manueller Erfassung.
ERP
SAP Business One
Service Layer / DI API
Zur Lösungsseite →ERP
Dynamics 365 Business Central
Standard-REST-API / AL-Extension
Zur Lösungsseite →ERP
myfactory
SOAP-API (bidirektional)
Zur Lösungsseite →ERP
Abacus
AbaConnect (XML/Webservices)
Euer System ist nicht dabei? Gut möglich, dass es trotzdem geht: Jedes ERP mit Import-Schnittstelle, API oder zugänglichem Datenmodell ist anbindbar — von Sage über SelectLine und weclapp bis zu historisch gewachsenen Eigenentwicklungen. Genau solche Integrationen sind unser Kerngeschäft als Custom-Business-Software-Manufaktur.
Rechnet sich das bei euch?
Fehlerfolgekosten anpassen (optional)
Geschätzter Jahreseffekt der Automatisierung
—
Erfassungskosten × 0,8 + Fehlerfolgekosten, bei 220 Arbeitstagen
Eingaben werden nicht gespeichert oder übertragen.
Drei Eingaben genügen für eine erste Antwort: Belege pro Tag, Minuten pro Beleg, Stundensatz. Wer lieber von Hand rechnet: Die vollständige Rechenlogik ist offen dokumentiert — inklusive Fehlerfolge- und Skontoeffekten. Als Faustregel: Ab 10–20 Belegen pro Tag wird Automatisierung regelmäßig deutlich rentabel; die Amortisation liegt typischerweise innerhalb des ersten Jahres.
Der Weg in den Produktivbetrieb
Phase 1 — Pilot (2–3 Wochen). ~10 echte Belege aus eurem Eingang, Gold-Set mit Soll-Ergebnissen, Pipeline läuft End-to-End bis zum Belegentwurf im Testsystem. Ein bewusst eingebauter Fehler muss gefangen werden — sonst ist Validierung Dekoration.
Phase 2 — Validierung (~100 Belege). Inklusive Absendern, die das System nie gesehen hat. Hier entstehen die Kennzahlen (Durchlaufquote, Positionsgenauigkeit) und die Schwelle, ab der automatisch übernommen wird.
Phase 3 — Produktivbetrieb. Go-live mit Review-Queue, Monitoring pro Absender, Korrekturen fließen zurück. Betrieb als Docker-Stack auf eurer Hardware — wartbar wie jeder andere Dienst.
Euer Aufwand: Beispielbelege bereitstellen, Schnittstellen-Zugang zum Testsystem, ein Ansprechpartner für Stammdaten-Fragen. Kein ERP-Großprojekt — ein präzise umrissenes Modul.
Warum kitun
Wir sind kein SaaS-Anbieter mit Konnektor-Katalog, sondern eine AI-native Software-Manufaktur: Senior-Architekten entwerfen die Pipeline entlang eurer Prozesse, Coding-Agents beschleunigen die Umsetzung, und was in Produktion geht, haben wir reviewt und verantworten es. Das Ergebnis ist exklusiv für euch gebaut — eure Daten, euer Betrieb, on-premise möglich. Dieselbe Architektur, mit der wir unsere eigenen Produkte bauen und betreiben.
Häufige Fragen
Was unterscheidet das von SaaS-Tools wie Workist, Konfuzio oder Parashift?
Drei Dinge: Eure Dokumente bleiben im Haus (on-premise statt Anbieter-Cloud), die Kosten sind fix statt volumenbasiert, und die Integration endet nicht am Standard-Konnektor — sie wird auf euer ERP und eure Stammdaten-Logik gebaut.
Welche Hardware brauchen wir?
Für mittelständische Volumina genügt eine einzelne 24-GB-GPU oder eine kompakte KI-Appliance mit großem Unified Memory — Größenordnung 2.000–4.000 Euro. Kein Cluster, kein ML-Team; der Betrieb entspricht einem normalen Docker-Dienst.
Wie lange dauert die Einführung?
Vom Kick-off bis zum Produktivbetrieb typischerweise wenige Wochen bis wenige Monate, abhängig von Belegvielfalt und Integrationsweg — die Phasen oben machen den Fortschritt jederzeit messbar.
Was passiert mit Belegen, die das System nicht sicher lesen kann?
Sie landen vorausgefüllt in der Review-Maske und sind in Sekunden geprüft. Jede Korrektur fließt zurück und verbessert die Pipeline — die Review-Quote ist eine fallende Kurve, keine Konstante.
Funktioniert das mit Scans und Papier?
Ja — gescannte und fotografierte Belege laufen über einen Vision-Pfad derselben Pipeline. Born-digital PDFs (der B2B-Normalfall) werden direkt über den Text-Layer verarbeitet, ganz ohne OCR.
Wie ist das Preismodell?
Einmalige Projektkosten plus geringe fixe Betriebskosten — keine Stückpreise, keine Volumenstaffeln, kein Abo-Zwang. Die Ersparnis bleibt vollständig bei euch; eine erste Rechnung mit euren Zahlen entsteht im Erstgespräch.
Trainiert ihr Modelle auf unseren Daten?
Nein. Die Pipeline nutzt fertige Open-Weights-Modelle; Verbesserungen entstehen über Prüfregeln, Beispiele und Schwellen — nachvollziehbar und reversibel. Eure Belege verlassen das Netzwerk nicht, auch nicht zu Trainingszwecken.
20 Minuten, eine ehrliche Einschätzung
Bringt zwei, drei typische Belege mit — wir sagen euch im Erstgespräch, was automatisierbar ist, was es kostet und ob es sich rechnet. Wenn nicht, sagen wir auch das.